ERSTELLUNG VON FOTOREALISTISCHEN BILDERN
Was ist Fotorealismus?
In diesem Kapitel soll es darum gehen, wie heutzutage fotorealistische Bilder erzeugt werden. Zuerst gilt es aber zu klären, was eigentlich Fotorealismus ist.
Die Antwort auf diese Frage hängt damit zusammen, wie wir Bilder wahrnehmen. Unser Auge funktioniert zwar ähnlich wie eine Kamera, jedoch unterstützt das Gehirn bei unserer Wahrnehmung. Als Beispiel kann man sich hier einen dunklen Raum vorstellen. In diesem Bereich befindet sich ein Fenster, durch das helles Tageslicht scheint. Befänden wir uns selbst in dieser Umgebung, würden sowohl die hellen Stellen als auch die dunklen von unserer Wahrnehmung für uns deutlich gemacht. Wir wären in der Lage, in beiden Extremfällen noch viel Detail zu erkennen. Sobald man versucht, ein Foto dieses Raumes zu machen, wird es jedoch komplizierter (vgl. Abb. 2). Eine Kamera fängt das Licht anders ein. Hier bestimmen mehrere Faktoren wie Blende, Belichtungszeit und die Empfindlichkeit des Sensors (ISO) wie das Foto später aussieht. Für die Technik ist es schwierig, sowohl dunkle als auch helle Details einzufangen. Ist das Foto für Elemente im hellen Fenster belichtet, stehen die Chancen in einem solchen Szenario hoch, das die Schattenpartien zu dunkel ausfallen. Das Gleiche passiert in dem Fall, wenn für Details im Schatten eingestellt wird. Dann wird das Fenster nur noch ein weißer Rahmen sein, in dem nichts mehr erkennbar ist. Wie genau unser Auge einfallendes Licht aufnimmt, wird in Kapitel 4 meiner schriftlichen Arbeit erklärt.

Abb. 2: Belichtungssituationen, überbelichtet (links), unterbelichtet (mitte) und simulierte Darstellung der menschlichen Wahrnehmung (rechts)
(VRUYR, 2018)
Trotzdem versucht man am Computer, Fotos realistisch zu imitieren. Warum machen wir das? Und nicht direkt die Welt, wie wir sie mit unserem Auge wahrnehmen? Eran Dinur hat hierfür eine Antwort. Er schreibt, dass bisher alle Abbildungen unserer Realität aus einer Kamera stammen. Fotografien und Filme entstehen mit einem Aufnahmegerät und wir sind deswegen so sehr an den „photographic look“ gewöhnt. Das heißt, der Versuch, die menschliche Wahrnehmung nachzubilden, reicht nicht. Da wir in allen unseren Aktivitäten mit Bildern oft auch mit Bewegtbildern konfrontiert werden, erkennen wir diese als real an (DINUR, 2021).
Aber inwiefern stimmt das? Bevor es die erste Kamera gab, waren die Menschen noch nicht an Fotografien gewohnt. Als Künstler in der früheren Zeit Porträts malten, waren diese dann in einem „artistic look?“. Landschaftsmalereien wurden früher durch die Sichtweise des Künstlers bestimmt. Die Ergebnisse sahen deshalb wie eine stilisierte Version der echten Welt aus. Warum müssen wir heute denn Fotos imitieren? Da wir heutzutage noch keine Abbildungen unserer Wahrnehmung aus dem Gehirn erstellen können sind wir diesen Anblick auch nicht gewöhnt. Sollten wir eine perfekte Abbildung unserer Sichtweise auf die Realität vor unser Auge halten, was würde dann passieren? Würde unsere Wahrnehmung dieses Bild trotzdem noch verzerren? Ich glaube, das Gehirn würde nach dem gewohnten Ablauf das Gesehene analysieren. Die aufgenommenen Informationen würden somit zweimal interpretiert: Einmal auf der Nachbildung unserer Wahrnehmung und in unserem Gehirn. Momentan wird es leider keine Antwort darauf geben. Zumindest nicht solange wir die reale Welt nicht vollständig nachbilden können.
Wenn Bilder und Videos in unserer Wahrnehmung als real gelten, dann sollten wir uns diese auch als Vorbild nehmen. Deshalb wollen wir mit unseren virtuellen Szenen einen fotorealistischen Eindruck hinterlassen. Denn wenn es wie ein Foto ist, dann wird es auch realer wahrgenommen (DINUR, 2021).
Um die Erstellung einer Computergrafik besser zu veranschaulichen, ist das folgende Kapitel in einzelne Abschnitte unterteilt. Diese orientieren sich an einem einfachen 3-D-Workflow. Angefangen wird mit dem Aufbau einer Szene und der Modellierung der Objekte (ABIDIN et al., 2003, S.390–395).
Szenenaufbau und Modellierung
Der Aufbau der virtuellen Szene kann eine Auswirkung auf den Betrachter des Endergebnisses haben. Gegenstände, die in der realen Welt nicht existieren können, oder Objekte mit ungewohnten Proportionen wirken unrealistisch auf den Betrachter (DINUR, 2021). Genauso kann die Planung einer Szene einen Effekt auf das Endresultat haben. Die Komposition eines Bildes ist in der Fotografie eine wichtige Komponente, gleicherweise sollte sie es auch in der Computergrafik sein. Ein durchdachter Bildaufbau steigert die Lesbarkeit und Immersion des Betrachters (ABIDIN et al., 2003, S.390–395).
Eine Szene sollte daher so konzipiert sein, dass sie auch in der echten Welt entstehen könnte. Die Objekte innerhalb der Umgebung sollten mit realen Maßen ihren Inspirationsquellen nach aufgebaut werden. Ein Detail, welches oft übersehen wird, sind scharfe Kanten (DINUR, 2021; vgl. Abb. 3). Ein perfekter Würfel mit 90° Kanten kann in der wirklichen Welt niemals existieren. Umso einfacher ist es in der virtuellen Welt, ein solches Objekt zu erzeugen. Abgerundete Kanten, kleine Kratzer und andere Aussparungen sind sehr wichtige Bestandteile eines Objektes. Sie verstärken die Form eines Körpers (vgl. Abb. 4). Oft ist es sehr mühselig, alle Details in einen Gegenstand hinein zu modellieren. Die kleinen Feinheiten werden deshalb eher später in Kapitel 2.3 mithilfe von Texturen umgesetzt.


Abb. 3: (links) Renderbild einer Tastatur. Die abgerundeten
Kanten der einzelnen Tasten fangen Lichter auf und sorgen für ein
besseres Verständnis von der Form.
Abb. 4: (rechts) Renderbild einer Tastatur in Gesamtansicht
Zwei der bekanntesten Modellierungstechniken sind das „Hard-Surface-Modeling“ und das „Sculpting“. Ersteres wird oft für hergestellte Gegenstände verwendet. Die Sculpting-Methode ist dem Töpfern nachempfunden und wird deshalb häufig für organische Modelle, wie zum Beispiel für Menschen, verwendet (GALYEAN und HUGHES, 1991, S.267–274). Mit diesen beiden Techniken lassen sich viele Objekte erzeugen.
Fotogrammetrie
Auf eine weitere Technik möchte ich hier eingehen, und zwar die der Fotogrammetrie. Der Name kommt ursprünglich aus dem Griechischen und heißt übersetzt ungefähr „mit Licht messen/mit Licht zeichnen“. Dies ist keine herkömmliche Modellierungsmethode. Es geht hauptsächlich darum, geometrische und semantische Informationen über Gegenstände zu erhalten. Die geometrischen Daten enthalten die Koordinaten eines Objektes und die Punkte die den Aufbau dessen beschreiben. Die semantischen Informationen helfen Objekte von anderen zu unterscheiden und eventuell Ungewolltes herauszufiltern (SCHENK, 2005; Stachniss, 2020).
Da der gesamte Prozess sehr umfangreich ist, wird in diesem Abschnitt nur der Aspekt der 3-D-Rekonstruktion behandelt. Bei der Erstellung von 3-D-Objekten mithilfe von Fotogrammetrie werden mehrere Fotos von einer Software analysiert. Hierbei müssen zwei Probleme beachtet werden. Das Bild welches als Input dient ist eine 2-dimensionale Abbildung unserer 3-dimensionalen Umgebung. Dementsprechend ist es sehr wichtig, anhand von semantischer Information unwichtige Gegenstände herauszufiltern. Das zweite Problem tritt bei dem Vergleich mehrerer Fotos auf. Der Algorithmus muss ein wiederkehrendes Objekt erkennen. Die Gegenstände müssen zwischen den Bildaufnahmen also genug Ähnlichkeit aufweisen, um erfasst zu werden. Im nächsten Schritt werden Kamerapositionen berechnet. Diese sind essenziell für eine Rekonstruktion eines Gegenstandes. Sobald die Positionen der Kameras bekannt sind, können mittels Triangulierung die Objektpunkte im Raum ermittelt werden (SCHENK, 2005; Stachniss, 2020). Wenn dieser Prozess um einen Körper herum angewandt wird, lässt sich bei einer guten Rekonstruktion das gesamte Objekt allein durch Fotografien nachbilden. Das erzeugte Modell kann dann in die 3-D-Szene eingefügt werden.
Die Fotogrammetrie kann als eine alternative Methode genutzt werden, 3-D-Gegenstände in eine Szene einzubauen. Dadurch, dass ein realer Körper „eingescannt“ wird, ist das Ergebnis auch schnell fotorealistisch. Ein guter Scan braucht jedoch Erfahrung und Zeit. Für eine schnelle Visualisierung gibt es Bibliotheken von professionell erstellten 3-D-Scans. Verschiedene Anbieter stellen unter einer angegebenen Lizenz bereits fertige Modelle zur Verfügung. Große und komplexe Szenen werden mit diesen Bibliotheken auch für Einzelpersonen ermöglicht (vgl. Abb. 5).

Abb. 5: Naturrender; schnelle Visualisierung von komplexen Szenen dank Modellbibliotheken.
Shading
Das Shading eines Objektes bestimmt zu einem sehr großen Teil dessen Realismuswirkung. Die Materialeigenschaften eines Körpers sorgen für akkurate Lichtverhältnisse in der Szene. Bei physikbasiertem Rendering (PBR) werden dafür Raytracing-Algorithmen verwendet. Für eine akkurate Darstellung unterschiedlicher Lichtcharakteristika werden vier Informationen berücksichtigt. Zuerst die Lichtquelle, denn ohne Licht bleibt alles schwarz. Danach der Kamerastandpunkt. Und zu guter Letzt der Einfalls- und Ausfallswinkel der Lichtreflexion in Relation zu Kamera und Lichtquelle.
Um die korrekte Darstellung von Licht zu gewährleisten gibt es drei unterschiedliche Funktionen.
- Die bidirektionale Streuverteilungsfunktion (BSDF) für generelles Streulichtverhalten
- Die bidirektionale Reflexionsverteilungsfunktion (BRDF) für korrekte Spiegelungen
- Die bidirektionale Transmissionsverteilungsfunktion (BTDF) für Lichtbrechungen
Mittels dieser Funktionen können physikalisch korrekte Lichtverhältnisse dargestellt werden (ABIDIN et al., 2003, S.390–395; PHARR und JAKOB, 2016).
Materialeigenschaften
Jedem Objekt in einer virtuellen Szene können Materialien zugewiesen werden. Die dazugehörigen Materialeigenschaften bestimmen das Aussehen des Körpers. Anhand von Blenders „Principled BSDF Shader“ möchte ich nun auf die unterschiedlichen Einstellungen eingehen (vgl. Abb. 6).
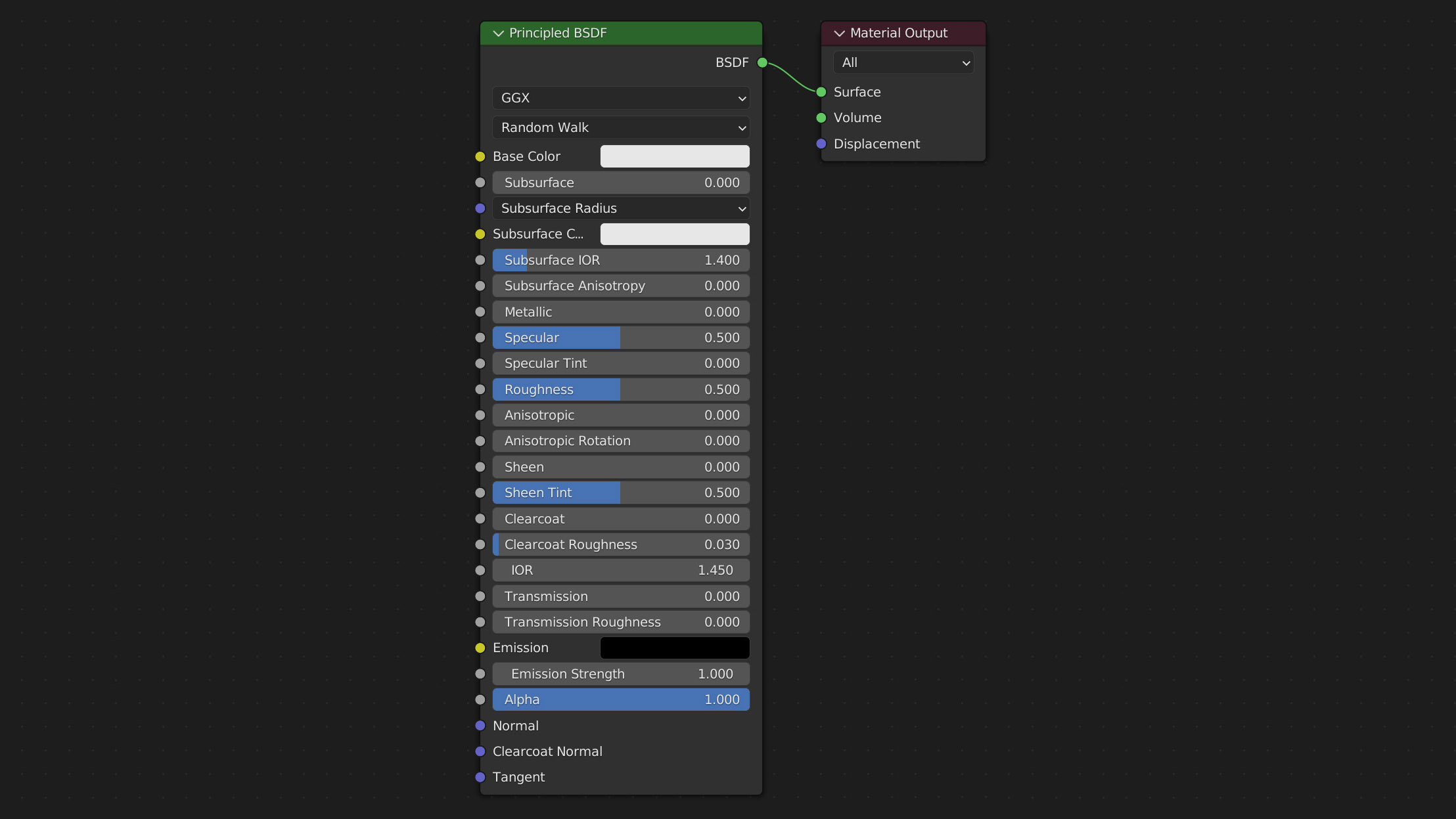
Abb. 6: Blenders Principled BSDF Shader Node und die angeschlossene Material Output Node.
Der Shader ist für physikbasiertes Rendering entwickelt worden. Durch die Zusammenfassung mehrerer Variablen soll der Shaderknoten (Node) eine universelle Lösung für viele Materialien bieten. Die Node ist als mehrschichtiger Shader zu betrachten. Zu Grunde liegend ist eine Schicht für Grundfarbe (Base color), Metallizität (Metallic), Untergrund Streuung (Subsurface) und Durchlässigkeit (Transmission). Darauf folgen eine spiegelnde (Specular), eine glänzende (Sheen) und eine Klarlackartige (Clearcoat) Schicht (Blender Foundation, 2022). Für eine klarere Übersicht werde ich die einzelnen Kanäle mit den englischen Namen betiteln. Die verschiedenen Eingänge der Node teile ich in drei unterschiedliche Kategorien ein. PBR-Kanäle, PBR-Helfer und weitere Einstellungen.
Texturen
Wenn wir von fotorealistischem Rendering sprechen, sind Texturen nicht mehr wegzudenken. Durch sie können wir die einzelnen Eingänge eines Shaders noch komplexer ansteuern. Anstatt zum Beispiel nur einen homogenen Farbton als Base color zu benutzen, kann eine Textur ein differenziertes, bildhaftes Farbmuster beinhalten. Sie sind also der Grund, warum wir heutzutage fotorealistische Materialien erstellen können.
Texturen gibt es in zwei unterschiedlichen Formen: Aus der realen Welt aufgenommen oder digital erstellt.
Fotografien und Videoaufnahmen stellen oft die Basis für ein Material dar. Der Grund dafür ist offensichtlich. Ein Foto der realen Welt spiegelt diese wieder. Also benutzen wir nur Fotoaufnahmen als Basis für Materialien und schon ist der Realismus garantiert? So einfach ist es leider nicht. Bei der Erstellung von Fototexturen müssen einige Dinge beachtet werden. Die Anzahl benötigter Texturen werden vom Material bestimmt, welches nachgestellt werden soll. Häufig sind Texturen für die Eingänge Base color, Metallic, Roughness und Normal vorhanden (vgl. Abb. 10). Kanäle, die sonst noch benötigt werden, folgen danach, zum Beispiel Specular oder Displacement.

Abb. 10: Detailliertes Texturenpacket für Sandstein. Abfolge von links nach rechts: Ambient Occlusion, Diffuse, Specular, Roughness, Normal, Bump und Displacement.
Dazu kommen die unterschiedlichen Datentypen, die die Eingänge des Shaders verarbeiten. Entweder sind es RGB-, Graustufen- oder Vektoren-Daten. Die meisten Kanäle arbeiten mit Float-Werten. Das sind Kommazahlen, die eine Eigenschaft beschreiben. Diese Float-Werte können innerhalb einer Textur auch in Graustufen angegeben werden. Wie beim Alphakanal bereits erklärt, ist null schwarz und eins weiß. Da die Abstufung der Werte in 8-Bit gespeichert wird, bleiben 255 Schritte von null nach eins. Beim Benutzen von Texturen muss hierbei allerdings auch noch der Farbraum beachtet werden. Der Standardfarbraum für Displays ist sRGB. In diesem Farbraum werden die Farben nach einem Gamma von 2,2 also nicht linear dargestellt (STARKWEATHER, 1998, S. 19). Das Farbprofil beim Laden einer Textur ist entscheidend, wenn sie in einem Material verwendet werden soll. Je nach Einsatzzweck einer Textur muss man die Interpretation der Software so anpassen, dass die Werte nicht verschoben werden. Gerade Graustufenwerte sollten deshalb als „Non-Color Data“ angegeben werden, um eine Gammakorrektur zu vermeiden. Die Höheninformationen einer Bump- oder Displacement-Map sollten immer linear angegeben werden.
Ein weiteres Problem bei Fototexturen ist die Auflösung. Heutzutage nehmen Spiegelreflexkameras zwar hochauflösende Bilder auf, aber man muss dennoch abwägen, welche Größe die richtige ist. Je näher das Objekt zur Kamera dargestellt wird, desto höher sollte das Detaillevel (LOD) auch sein. Generell sollte eine Textur mindestens die Endauflösung des Renderbildes haben. Um sicherzugehen, dass keine Renderartefakte entstehen, ist es ratsam, sich an das Nyquist-Shannon-Abtasttheorem zu halten. Die Texturauflösung sollte also im Optimalfall also mindestens doppelt so hoch sein. Die Größe eines Objektes spielt hierbei auch eine Rolle. Wenn eine Textur auf eine große Fläche gestreckt werden soll, wird sie häufig durch den Einsatz von bilinearer Interpolation unscharf. Deshalb werden Fototexturen oft wiederholt angelegt. Die Texturen müssen aber für dieses Vorhaben angepasst werden. Eine nicht nahtlos wiederholbare Textur wird deutliche Kanten im Ergebnis liefern. Genauso verhält es sich mit größeren, schnell wiedererkennbaren Details in dem Foto (vgl. Abb. 11).

Abb. 11: Interaktive Darstellung einer Textur für Sandstein. Einfache Darstellung (Normal) und fünffach wiederholt (bei Maushover), es fallen deutliche Wiederholungsmuster auf.
Zusätzlich zu all diesen Punkten kommt der Fakt, dass die verschiedenen Kanäle unterschiedliche Informationen benötigen. Eine Roughness-Map ist nicht erstellt, indem man ein Foto in Graustufen konvertiert. Mit einem guten Auge für Details müssen die glatten oder rauen Reflexionen erkannt werden. Automatisierungsmethoden wie ein „Hochpass-Filter“ helfen bei diesen Vorgängen nur bedingt. Im Falle von Spiegelungen kann dieser die Glanzlichtstellen isolieren. Bei einer Displacement-Map ist das nicht so leicht. Nur weil etwas einen hohen Helligkeitswert in Schwarz-Weiß hat, heißt das nicht, dass das Detail höher liegt als der Durchschnitt.
Foto- und Videotexturen zu verwenden macht also Sinn. Jedoch ist die eigene Erstellung dieser sehr komplex und erfordert viel Zeit. Wie auch bei der Fotogrammetrie können hier Bibliotheken für Materialien weiterhelfen.
Und es gibt noch eine weitere Art der Texturen. Prozedural generierte Texturen sind mathematische Beschreibungen von Formen (vgl. Abb. 12). Diese Struktur beginnt in Graustufen und kann später eingefärbt werden. Das wohl nützlichste Tool eines 3-D-Artists ist die „Noise Texture“. Rauschen entsteht überall. Egal ob verschiedene Farbpigmente in der Wolle einer feinen Decke oder das auch als „Film Grain“ bekannte Artefakt bei Aufnahmen mit sichtbarem Silberkorn in hochempfindlichen Filmen. Noise Texturen generieren ein zufälliges Rauschen von Weißen und schwarzen Flecken. Diese können nach Belieben verändert werden und so für jeden Fall angepasst werden.

Abb. 12: Prozedural generierte „Noise“. Auch bei reingezoomter Ansicht besitzt diese noch sehr hohe Details (rechts).
Ein maßgeblicher Vorteil dieser prozeduralen Texturen ist, dass sie sehr „lightweight“ sind. Sie benötigen kaum Rechenleistung, sind unendlich groß und detailliert. Warum also nicht nur prozedurale Texturen verwenden?
Obwohl diese Art von Textur sehr wohl vorteilhaft sein mag, ist die Erstellung einer fotorealistischen Textur hochkomplex. Ein tiefgründiges Know-how ist von Nöten, um gute prozedurale Texturen zu erzeugen. Viele 3-D-Softwares bieten heutzutage mehrere unterschiedliche Generatoren an, die Texturen erzeugen können. Aber auch wenn diese zufällig berechnet sind, haben sie oft einen „generierten Flair“. Die Modelle, die als Vorlage für die Berechnung dienen, scheitern häufig an dem Detailgrad in einer natürlichen Umgebung.
Wie so oft haben also der Einsatz von Foto- und prozeduralen Texturen Vor- und Nachteile. Ein Mix aus beiden kann eine starke Methode sein, ein überzeugendes Ergebnis zu schaffen.
Lighting
Lichtverhältnisse einer Szene bestimmen Charakter und Stimmung des Endergebnisses. Um ein realistisches Bild zu erzeugen, müssen also auch Lichter beachtet werden. Ein Standard-Tool in einer virtuellen Umgebung sind Punktlichter. Diese strahlen eine bestimmte Menge Licht von einem einzigen Punkt aus ab. Fast so wie LEDs. Leider nur fast, selbst LED-Lampen lassen sich nicht auf einen winzigen Punkt festlegen. Anstelle von Punktlichtquellen sollte man also Lichtquellen verwenden, die eine Fläche besitzen.
Die „Illuminating Engineering Society“ (IES) hat verschiedene Lichtcharakteristika in ein digitales Format übersetzt (DINUR, 2021). Mit diesem lassen sich reale Lichtquellen über die Interpretation von Daten nachbilden. Das ist besonders nützlich für Szenen, die versuchen echte Lampen zu imitieren.
Zu einfachen Lichtquellen kommen noch Diffusoren dazu (vgl. Abb. 13). Sie sind ein wichtiger Teil beim Lighting einer Szene. Hartes Licht gibt es eher selten, deshalb sollten weichere Lichtquellen verwendet werden. Milchglas, Stoffe oder Lampenschirme blocken die direkten Lichtstrahlen einer Leuchtquelle ab und verteilen es auf einer teilweise durchlässigen Oberfläche. Dadurch sinkt die Intensität des Lichtes ein wenig, jedoch werden durch die vergrößerte Fläche die Schatten weicher. Bei der Benutzung von diffusen Schirmen über Lichtquellen und IES-Daten können also auch Punktlichter eine realistische Wirkung erzielen.

Abb. 13: Direktes hartes Licht (links) und abgeschirmtes diffuses Licht (rechts).
All das ist nützlich für Visualisierungen in Innenräumen. Aber was ist, wenn eine Naturszene dargestellt werden soll? Die Sonne ist eine zu große Fläche, um sie mit Flächenlichtern nachzubauen. Durch die riesige Distanz zwischen Sonne und Planeten fallen die Lichtstrahlen fast parallel auf unsere Erde. Die minimalen Unterschiede in den Winkeln für eintreffende Sonnenstrahlen sind vernachlässigbar. Für diesen Fall gibt es eine Sonnenlichtquelle. Die Position dieses Lichtes spielt keine Rolle. Die Rotation gibt die Richtung der parallel einfallenden Lichtstrahlen an.
Der Himmel ist der nächste Einflussfaktor auf das Ergebnis. In reflektierenden Objekten spiegeln sich blauer Himmel und Wolken wieder. Das Blau, das unsere Atmosphäre erzeugt, wirkt sich auf die Farben aller Modelle in der Szene aus. Viele Renderengines kommen heutzutage mit einer Textur für den Himmel. Darin eingebaut sind bereits Effekte wie das Rayleigh- und das Mie-Scattering (DINUR, 2021). Eine solche Textur ist also prozedural generiert. Aber wie im vorherigen Abschnitt bereits erwähnt, sieht man bei generierten Texturen häufig einen „künstlichen Look“. Eine alternative zu diesen Texturen sind sogenannte „HDRI-Maps“ (vgl. Abb. 14).

Abb. 14: High-Dynamic-Range-Image, das als Lichtquelle in einer 3-D-Szene verwendet werden kann.
Diese „High-Dynamic-Range-Image-Maps“ beinhalten eine 360° Aufnahme der echten Welt. Dieses Bild wird von der Renderengine als Lichtinformation interpretiert und „strahlt“ auf die Szene. HDRIs sind ein sehr gutes Mittel, um reale Umgebungen in ein Renderbild zu integrieren. Genau wie bei Fototexturen für Materialien sind HDRI-Maps ein einfacher Weg, um Fotorealismus zu erzeugen.
Nur mit ein paar IES-Lichtern und einer HDRI-Map ist eine Szene nicht zwingend fertig ausgeleuchtet. Die Atmosphäre der Erde verändert die Darstellung von Gegenständen noch mehr. Je weiter Objekte entfernt sind, desto heller werden sie. Staub, Smog oder Nebel sind feine Teilchen in der Luft. Einkommende Lichtstrahlen werden von diesen Partikeln beeinflusst. Wenn man bei Nebel gegen Licht sieht, fallen einem sogenannte „God-Rays“ auf. Die Lichtstrahlen werden sichtbar. Jeder kennt das Experiment mit einem Nebelwerfer und einem Laserpointer. Genauso werden bei dichtem Nebel die Lichtstrahlen deutlicher.
Diese atmosphärischen Effekte kann man auch im virtuellen Raum simulieren. Ein Material hat hierfür zwei Ausgänge. Die Oberfläche und das Volumen des Körpers. Um einen Würfel mit Nebel zu füllen, schließt man also keinen „Pricipled-BSDF-Shader“ an die Oberfläche an. Stattdessen benutzt man einen sogenannten „Volume-Shader“. Dieser berechnet dann einen Nebel innerhalb des Würfels. Über die Einstellungen des Volume-Shaders kann die Dichte des Dunstes angepasst werden. Außerdem hat der Shader weitere Einstellungsmöglichkeiten für andere Aerosole. Wolken, Flammen oder Rauch können damit auch dargestellt werden.
Gerade für das Lighting kann Feuer interessant sein. Über die Dichte des volumetrischen Shaders können Stellen bestimmt werden, die Flammen enthalten sollen. Diese sind wiederum an eine Emissionseinstellung geknüpft. Dadurch entsteht ein selbst leuchtendes Feuer.
Volumetrische Berechnungen sind allerdings sehr rechenaufwendig und erzeugen oft ein hohes Rauschen im Endbild. Um diese Rechenleistung einzusparen, werden Nebel und Dunsteffekte meist im Nachhinein auf das Bild gerechnet.
Rendering
In der Einleitung dieser Arbeit wurde die Geschichte der Computergrafik kurz erläutert. Nach den Rasterisierungsverfahren wurden Raytracing Algorithmen verwendet, um realistischere Renderbilder produzieren zu können. Eine kurze Wiederholung: Raytracing berücksichtigt einzelne Lichtstrahlen in einer Szene. Diese Rays werden nicht wie in der realen Welt von der Lichtquelle aus berechnet, sondern von der virtuellen Kamera aus. Die Berechnung erfolgt also rückwärts von jedem Pixel der Bildebene aus.
Dabei tritt jedoch schnell ein Problem auf. Was, wenn mehrere Lichtquellen auf einer Stelle zusammenkommen? Würden die Strahlen sich in diesem Fall für ein Licht entscheiden? Oder sich aufteilen? In der Realität teilen sich die Lichtstrahlen in eine Kaskade von weitere Lichtstrahlen auf. Die Menge von unterschiedlichen Glanzlichtern, diffusen Spiegelungen oder Transmissionsstrahlen wäre viel zu viel, um alles auf einmal zu berechnen. Stattdessen werden Strahlen in unterschiedlichen „RenderPasses“ abgeschickt. In mehreren Durchgängen werden so verschiedene Lichtstrahlen berechnet.
Um bei der Berechnung der einzelnen Render-Passes Zeit zu sparen, wird der Monte Carlo Ansatz genutzt. Das ist eine Methode, bei der stichprobenartig Berechnungen gemacht werden. Es werden also nicht alle Lichtstrahlen berechnet. Stattdessen werden einzelne Berechnungen an unterschiedlichen Stellen durchgeführt (KROESE und RUBINSTEIN, 2012, S.48–58). Die Anzahl der Proben (Samples) variiert von Renderengine zu Renderengine. Meistens lässt sich diese Zahl auch konfigurieren, um ein klareres Ergebnis zu erhalten.
Eran Dinur erklärt das ganze ein wenig bildlicher. „The concept is similar to statistical surveys: to find out which ice cream flavour is the most popular in the USA, for example, the surveyor would never interview the entire population (which will give the most accurate result but will take forever), but a much smaller selected group instead (which will give a reasonably accurate result in a manageable time).“ (DINUR, 2021).
Der Monte Carlo-Ansatz ist also nicht mehr wegzudenken. Nach der Einführung von Monte Carlo wurde das sogenannte Pathtracing eingeführt. Dies ist eine Weiterentwicklung vom Raytracing. Der Unterschied liegt in der Bewertung der Lichtstrahlen. Pathtracer behandeln direktes und indirektes Licht gleich. Weil nun beide Formen von Beleuchtung gleichwertig berechnet werden, tritt der Effekt der globalen Illumination (GI) sichtbarer auf. Indirekte Lichter haben einen großen Einfluss auf den Realismusgrad eines Bildes (DINUR, 2021). Durch indirekte Beleuchtung beeinflussen Farben von umliegenden Objekten die Szene. Das sorgt für eine bessere Integration der Gegenstände innerhalb der Szene. Mit der heutigen Rechenleistung und den Optimierungen kann Global Illumination vollständig mit in die Szenerie einberechnet werden.
Weitere Vorschläge wurden über die Zeit entwickelt, um das Pathtracing noch schneller zu machen. Das „Bidirektionale Pathtracing“ ist eines dieser Vorschläge. Hierbei sollen die Rays jeweils von Licht und virtueller Kamera ausgehen und dementsprechend berechnet werden. Sogenannte „Shadow Rays“ sollen in diesem Monte Carlo-Ansatz die Strahlen miteinander verknüpfen. Das verkürzt die Berechnungszeiten (LAFORTUNE und WILLEMS, 1993).
Ist eine solche Methode heutzutage in Benutzung? Die genauen Arbeitsweisen eines Pathtracers werden nicht kommuniziert. Die genutzten Techniken sind ein größeres Puzzleteil in der Programmierung eines guten Pathtracers. Da macht es Sinn, dass große Konzerne das Erfolgsrezept ihrer Renderengines nicht verraten wollen. Lediglich quelloffene Programme wie Blender erlauben einen Einblick in die Softwarestruktur.
Ist es nicht widersprüchlich, alles daran zu setzen, realistische Szenen aufzubauen, nur damit die Renderengine danach schätzt, wie das Bild aussehen könnte? Ich würde sagen, ja und nein. Denn genau wie bei dem Beispiel der Lieblingseissorte der USA führt eine gründliche Stichprobensuche auf ein richtiges Ergebnis. Man muss also nur detailliert genug sein.
Welche Renderengine ist denn nun gründlich und welche ist es nicht? Es gibt zwei Typen von Renderengines. Unvoreingenommen (unbiased) und voreingenommen (biased). Unsere Augen wären eine vollständig unbiased arbeitende Renderengine. Eine nicht im Voraus festgelegte Reihenfolge an physikalischen Phänomenen treffen aufeinander, um zum Schluss in unserem Gehirn ein Bild zu erzeugen. Allerdings bestimmen Faktoren im Gehirn die Wahrnehmung noch weiter. Auf die menschliche Wahrnehmung gehe ich in meiner schriftlichen Arbeit ein.
Dadurch, dass bei den Berechnungen eines Pathtracers immer wieder Annahmen getroffen werden, sind diese jederzeit voreingenommen. Online gibt es häufig Diskussionen darüber, welche Renderengine „die beste“ sei. Dabei macht der Vergleich eher wenig Sinn. Unterschiedliche Engines sind für verschieden Zwecke ausgelegt. Blender ist zum Beispiel dafür gedacht, ein Allroundpaket zu liefern. Wie im Kapitel Shading bereits genannt, soll der Principled Shader ein umfassendes Paket darstellen, mit dem sich die meisten Materialien abbilden lassen.
Eine klare Antwort auf die oben erwähnte Frage gibt es also nicht. Aber die Ergebnisse der unterschiedlichen Anbieter sprechen für sich. Fotorealismus zu erzeugen ist heutzutage so einfach wie nie. Ob mit hochprofessioneller Software wie Pixars „Renderman“ oder mit Open-Source-Freeware wie Blender können überzeugende Renderings erstellt werden (vgl. Abb. 16).
Wie bereits erwähnt, wird ein Renderbild mit mehreren Passes brechnet. Auch im Nachhinein lassen sich die einzelnen Berechnungen separat ausgeben. Das kann man als Aufteilung eines Bildes in die unterschiedlichen „Lichtebenen“ verstehen. Je mehr dieser Ebenen zusammengesetzt werden, desto mehr sieht die Darstellung wie das Endergebnis aus. Der Vorteil dieser Strategie liegt darin, dass man einzelne Details auch im Nachhinein noch verändern kann ohne den Rendervorgang wiederholt starten zu müssen. Gerade bei Film- und Videoproduktionen ist dies nicht wegzudenken.
Über die Passes können direkte und indirekte Lichter voneinander getrennt bearbeitet werden. Ist das Glanzlicht zu dunkel, kann dies separat aufgehellt werden. Stimmt die Farbe eines Objektes nicht, kann dies mit einer einfachen Farbkorrektur behoben werden. Bei einer solchen Bearbeitung darf man das Ziel nicht aus den Augen verlieren. Für ein fotorealistisches Ergebnis können kleine Anpassungen hilfreich sein. Aber das Renderbild sieht aus einem guten Grund so aus, wie es berechnet wurde. Beim PBR werden Energieerhaltungsgesetze, Lichtintensitäten und vieles mehr realen Erfahrungswerten nachempfunden. Bei einer exzessiven Bearbeitung eines Bildes verfälscht man also eher das Ergebnis, als einen fotorealistischen Look zu wahren.
Abb. 16: Interaktive Zusammenfassung des unterschiedlichen Render-Passes.
Post-Processing
Was kann man also tun, um den Realismusgrad eines Renderbildes in Bezug auf fotografischen Realismus noch weiter zu erhöhen?
Ein paar Effekte bei Fotografien treten auf, weil diese mit einem Objektiv aufgenommen wurden. Dieses Objektiv besitzt eine Linse im Inneren. Auch bei ständiger Reinigung kommt es immer wieder zu Unreinheiten. Staub oder andere Flecken können sich auf einem Bild bemerkbar machen (vgl. Abb. 17). Sie verleihen einem Foto einen „träumerischen“ Stil. Der Einsatz dieser feinen Unreinheiten hellt das Bild ein wenig auf. Größere Schäden an einer Kamera können vorkommen. Auch sie lassen sich auf einem Bild wiederfinden. Kratzer in einer Linse oder Dreck auf dem Kamerasensor sind hier gemeint. Diese Imperfektionen spiegeln sich als dunkle Punkte auf einem Foto wieder. Es kann nützlich sein, auch mögliche Schäden einer Kamera nachzubilden. Beschädigungen innerhalb eines Bildes können Zeitverweise darstellen.
Die Linsen eines Objektivs sorgen für Lichteffekte. Die sogenannte Lens Flare ist sehr bekannt. Heutzutage ist sie Teil in jedem Hollywood-Blockbuster. Eine Lens Flare entsteht, wenn eine oder mehrere Linsen im Kameraobjektiv verbaut sind. Diese Linsen spiegeln, wie im Kapitel Shading erklärt, 4–8% des einfallenden Lichts. Deshalb kommt es zu diesen Blendenflecken. Die Form einer Lens Flare wird durch die Kamerabauweise bestimmt. Irisblenden gibt es in verschiedener Ausführung und unterschiedliche Kameramodelle haben andere Lens Flares. Eine Linsenreflexion kann von rund über oval bis zu einem Hexagon aussehen. Es hängt davon ab, wie sich die Irisblende der Kamera öffnet und wieder schließt. In der Form der Öffnung erscheint dann auch die Lens Flare.
Eine Objektivlinse beeinflusst das Endergebnis noch weiter. Eine „Lens Distortion“ verzerrt das Foto. Parallele Linien scheinen auf einmal nicht mehr gleich zueinander zu verlaufen. Häufig äußert sich eine Linsenverzerrung bei Weitwinkelobjektiven. Der Effekt ist sehr subtil und auf den ersten Blick nicht wirklich entscheidend. Allerdings sind es diese kleinen Änderungen, die ein Bild auf eine fotorealistische Stufe heben. Es lohnt sich also, die zuvor gut geplante Komposition ein wenig zu verzerren.
Chromatische Verschiebungen treten auf, weil Glaslinsen Lichtstrahlen mit unterschiedlicher Wellenlänge verschieden brechen. Bei scharfen Kanten in einem Foto kann man diesen Effekt häufig als Farbsäume erkennen. Chromatische Verschiebungen werden wie Linsenverzerrungen gar nicht deutlich wahrgenommen. Trotzdem senden sie unterbewusst die Signale, dass das Gesehene aufgenommen wurde. Es sind also wichtige Mittel, um einem virtuell erzeugten Foto ein Hauch Realismus zu verpassen.
Jeder, der selbst schon einmal versucht hat zu fotografieren, kennt das Problem. Man möchte einen Moment einfangen und das Bild ist unscharf. In einem solchen Fall gibt es keine andere Lösung als das Foto neu aufzunehmen. Unschärfe ist allerdings nicht immer schlecht. Die meisten Fotos besitzen Schärfentiefe (Depth of Field, DOF). In einer computergenerierten Szene ist allerdings alles gleich scharf dargestellt. Egal ob ein Haus direkt im Vordergrund oder die Skyline einer Stadt im Hintergrund. Depth of Field muss also im Nachhinein dazu gerechnet werden. Virtuelle Kameras kommen mit der Einstellungsmöglichkeit für Schärfentiefe. Wie bei einem realen Fotoapparat lassen sich Blende und Fokusdistanz einstellen. Teilweise gibt es sogar Einstellungsmöglichkeiten für die „simulierte“ Irisblende der virtuellen Kamera. Die Schärfentiefe zu rendern ist ein sehr leistungsaufwendiger Prozess. Dazu kommt, dass die Schärfenebene danach festgelegt ist. Sollte man den Fokus im Nachhinein ändern wollen, muss man das Bild erneut rendern.
Um korrekte Unschärfe auch nach dem Rendern in ein Bild zu integrieren, können „Blur“ oder „Defocus“ Filter verwendet werden. Damit diese eine adäquate Berechnung von Depth of Field erzeugen können, benötigen sie Informationen aus der virtuellen Szene. Ein sogenannter „Depth-Pass“ ist ein Light-Path der die Tiefeninformation einer Umgebung mit einem Schwarz-Weiß-Verlauf darstellt. Je näher ein Objekt zur Kamera steht, desto weißer ist es und umgekehrt. Über diese Information kann in den Filtereinstellungen ein Fokuswert bestimmt werden. Danach wird alles außerhalb der Schärfenebene über einen Blur-Filter unscharf gezeichnet.
Ein spezieller Fall von Unschärfe ist „Motion Blur“. Sich bewegende Objekte werden immer unschärfer, je länger die Belichtungszeit einer Kamera ist. Diesen Umstand müssen wir in der virtuellen Umgebung beachten. Gerade im Bereich der visuellen Effekte für realistische Szenen ist die Integration von computergenerierten Objekten ein wichtiger Aspekt. Diese heben sich jedoch vom Rest des Bildmaterials ab, wenn sie als einziges Element keine Bewegungsunschärfe besitzen. Um ein überzeugendes Ergebnis zu liefern, muss also bei bewegtem Material auf Motion Blur geachtet werden.
All die eben beschriebenen Effekte treten in der realen Welt auf, weil eine Spiegelreflex- oder Filmkamera und mehrere Linsen verwendet werden, um ein Foto aufzunehmen. Eine virtuelle Kamera ist aber keine Simulation einer echten. Deshalb ist es in der Nachbearbeitung von Renderbildern sehr wichtig, diese Phänomene darzustellen. Durch die Integration von Lens Flares, Unschärfe und chromatischer Verschiebung wird das Bild noch glaubwürdiger. Einem Betrachter müssen diese Effekte nicht als Erstes auffallen, um zu wirken. Wie bereits erwähnt sollte man sein Ziel im Auge behalten. Ein hochbearbeitetes Renderbild kann stilvoll erscheinen, aber nicht zwingend fotorealistisch.
Einen kurzen Anhang möchte ich zum Thema Postproduktion hinzufügen. Und zwar über „Color Grading“. Die Bearbeitung von Farben, Intensitäten oder Helligkeiten können große Unterschiede in der Bildsprache machen. Meistens wird Farbkorrektur als Stilmittel verwendet, um eine gewisse Stimmung hervorzurufen. Dafür muss man sich nur einige Hollywood-Blockbuster anschauen. Der Film „300“ von Zack Snyder stach 2006 durch die intensive Farbkorrektur heraus (300, 2007).
Farbkorrektur kann aber auch bedeuten, einen gewissen Filter anzuwenden. Im Besonderen kann mit Schwarz-Weiß- oder Sepiafiltern die Stimmung eines Bildes in der zeitlichen Wahrnehmung eingeordnet werden. Ein fotorealistischer Render mit dem richtigen Color Grading kann also auch wie ein Analogfoto aussehen.
In diesem Kapitel wurden die aktuellen Methoden erklärt, wie ein fotorealistisches Renderbild zustande kommt. Im kommenden Abschnitt möchte ich auf Probleme eingehen, die während der Erstellung eines solchen Bildes vorkommen können.
Abb. 17: Interaktive Zusammenfassung der verschiedenen Post-Processing Effekte.